.png)
大家好,见字如面。我是教授老边。本专栏将基于我个人的观察,为大家带来关于图数据库技术的分享。从基础概念出发,深入剖析算法逻辑,分享实际应用案例,探讨市场现状,展望未来趋势,希望能为大家带来图相关知识,引发思考与启发。让我们一同踏上这场图数据库技术的探索之旅 。
本篇文章系应广大读者的要求,将在天奕TGES专题讲座金融人工智能发展、Deepseek应用与分享管理的内容进行全文分享。期待与大家进行更多的交流与探讨 。
当下 AI 价值链条,其实是个倒三角形结构,见下图所示。
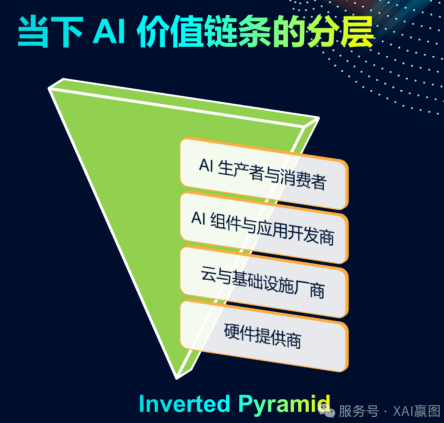
底层是硬件提供商,在全球范围内,硬件提供商数量极少,由少数寡头掌控;第二层是云和基础设施的厂商,同样,这类厂商在全球的数量也相当有限;第三层是各类 AI 组件、工具、应用的开发商。这一层数量增多,众多 AI 创业公司以及大模型厂商都涵盖其中,部分厂商业务可横跨多个层级;顶层是大量的 AI 内容生产者与消费者。其数量庞大,理论上可与全球人口数量相匹配 。
我们如果去归纳总结一下,大家可以看到这么几点:
· 在这个价值链条上,绝大多数的利润实际上是被芯片厂商如NVIDIA所获取,它实际在硬件层面上是一种算力的垄断。
· 那么可以想见的是,现在包括未来相当长一段时间内,云厂商与基础设施厂商会拿走剩下的那一大部分的利润。当然它也会面对,比如说它内部的这种大模型的血拼与开发的成本压力。
· 在AI价值链条的第三层,AI应用厂商之间的竞争极为激烈。无论是在垂直细分领域,还是通用人工智能领域,都呈现出明显的红海市场特征,厂商们激烈角逐、竞争白热化。以Deepseek(以下简称DS)的崛起为例,它的出现进一步降低了行业门槛。使得原本有一定难度的AI应用开发,变得更具普适性,大家都有了参与竞争的机会,即“你能做,我能做,他也能做,人人都能做”,这种局面无疑让竞争愈发激烈,未来的竞争态势将更加严峻和激烈。
· AI价值链条的最后一层,其受众几乎涵盖了地球上的全人类。人类既是AI的最终接收端,同时也参与AI相关内容的生产。然而,在整个价值链条里,这一层处于最低端的位置。从角色来看,人类不仅充当着数据生产者与内容生产者的角色,还为AI产品的训练提供了素材。但值得思考的是,人类在付出这些的同时,究竟能从AI发展中获得多少实际的益处,这一问题有待深入探讨和研究。
还有几个点总结出来。行业的利润显然严重的不均衡,最核心、最底层的那几个玩家,他们吞噬了绝大部分的利益。同时,我们也要看到,底层的云厂商和硬件厂商具有先天优势,他们早已拥有一套现成的基础设施(Infrastructure),得以借助AI发展的契机,顺势获取更多利益,可谓是坐收渔翁之利 。
再往上看,应用层基本上就是完全陷入到价格战,企业可选择的策略有限。要么选择开源,以吸引用户和市场份额;若产品价格过高,很快就会被竞争对手替代。在中国市场,这种激烈的竞争尤为突出。尽管AI应用层在中国尚处于起步阶段,但竞争的激烈程度已然超乎想象。此外,中国在高端算力方面,目前几乎依赖国外的供应,这对行业发展形成了一定的制约。回顾过去两到三年,大量大模型厂商如雨后春笋般涌现,大模型领域对于中国的创业企业和公司而言,似乎一下子变得没有了进入门槛。然而,在如此繁荣的表象之下,盈利情况却不容乐观。究竟有多少厂商能够真正实现盈利,即便有厂商声称盈利,其数据的可信度也值得怀疑。
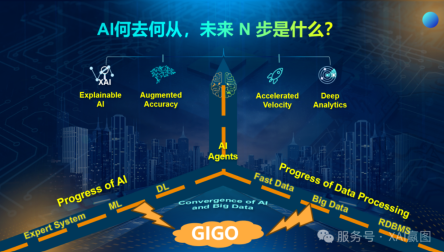
再看第二个部分,我们来探讨 AI 何去何从。如果把目光放得更长远,设想 AI 未来前进的一步、两步、三步,乃至 N 步,它的未来究竟是什么样的呢?这就需要我们审视 AI 整个基础架构的建设。本质上,它伴随着过去四五十年 IT 的发展,或者说是数据处理能力的发展,这存在两条脉络、两条线索,呈现出一种聚合和融合的态势。
早期的数据处理以及数据库技术的发展或许大家并不熟悉,但早期阶段相对初级,不太关键。简单来说,从 20 世纪 70 年代关系型数据库兴起,到 20 多年前互联网崛起催生了大数据处理框架,后来又出现了快数据。从查询语言的角度看,80 年代 SQL 诞生并成为国际化规范,之后大量 NOSQL 类型数据库处理形态涌现。值得注意的是,去年从业界标准层面出现了图的查询语言(GQL)标准,这标志着数据处理进入了一个全新阶段。
接着看 AI 的发展历程。在 20 世纪 80 年代和 90 年代,全球范围内存在所谓的专家系统,但到了 90 年代,这一系统发展陷入长达 10 年的低谷期。大约 30 年前我上大学时,如今许多国内外的资深 AI 专家,当时在高校里都深感困惑。随着互联网数据处理方面的发展,大约二十年前,机器学习开始蓬勃发展,这一热潮持续了十几年。过去这十几年,AI 一直热度不减,以从做显卡起家的英伟达为例,大概在十几年前,人们发现用 GPU 处理数据,方式简单粗暴,通过并发处理,实现了 “大力出奇迹”。实际上,如今整个 AI 领域,包括大模型、生成式 AI,本质上都是在这种 “大力出奇迹” 的框架、思想指导下发展起来的。如今,AI 看似前景光明,在 AI 和大数据处理的融合方面,我们看到一个重要的体现,即业界应用中的 AI Agents,或者大量的 AI Copilot。然而,这真的代表 AI 的终极发展归宿吗?我认为并非如此。即便不探讨真正的通用智能 ——AGI(Artificial General Intelligence),仅从几个维度分析就能看出。
第一个维度是模型的可解释性。如今整个 AI 模型的数量是可以量化的,其中有多少模型是可以解释的至关重要,因为 AI 最终是要代替人、辅助人做决策的。如果模型是黑盒的,人们很难放心使用。
第二个维度是准确度。英文里有个词叫 “Gut feeling”,中文即 “直觉”、“幻觉”。以图片识别为例,统计出来的准确率可能有 98.1%,但在金融行业使用过 AI 的人都清楚,当 AI 模型应用于金融数据时,准确率能达到 80% 都实属罕见。
第三个维度是速度,这其中也包括效率和成本。当前 AI 的成本较高,DS 的出现让大家看到了成本大规模降低的可能性(前提是其所宣称的都属实)。但从技术角度看,这其中存在着权衡取舍。若研究过 DS 的源代码,就会知道其中存在哪些取舍,比如可能牺牲精度,当然它也有积极的一面,例如大规模并发,这确实充分利用了底层硬件的算力。整体而言,利弊皆有,需要我们进行客观分析。
此外,AI 还有一个有趣的现象。很多普通用户在让 AI 生成一些看似一本正经胡说八道的内容时,会觉得很不错。但这里要说的是深度分析(Deep Analytics),数据摆在那里,AI 真的具备深度关联分析或者因果分析的能力吗?
很多数据之间是存在由因到果的关系——存在从 A 到 B 到 C,一直到 D 到 E 到 F 这样的深度链路。目前虽然所有的 AI 工具都在朝着具备深度分析能力的方向发展,但实际上并没有真正做到这一点,并不存在真正的深度分析能力。有一个经典的例子,维基(Wikipedia)的数据里隐藏着重大历史事件、人物、创造发明、战争之间的关联关系。现在去问全世界任何一个 AI,“成吉思汗” 和 “牛顿” 之间有怎样强烈的因果关联关系?没有任何一个 AI 能明确无误、精准地给出答案。要知道,所有的 AI 模型大概率都经过维基百科数据的训练(用百度百科也能达到类似效果),可遗憾的是没有任何一个 AI 能算出来。这表明它们根本没有进行这种深度的训练,依旧是基于概率的暴力组合。
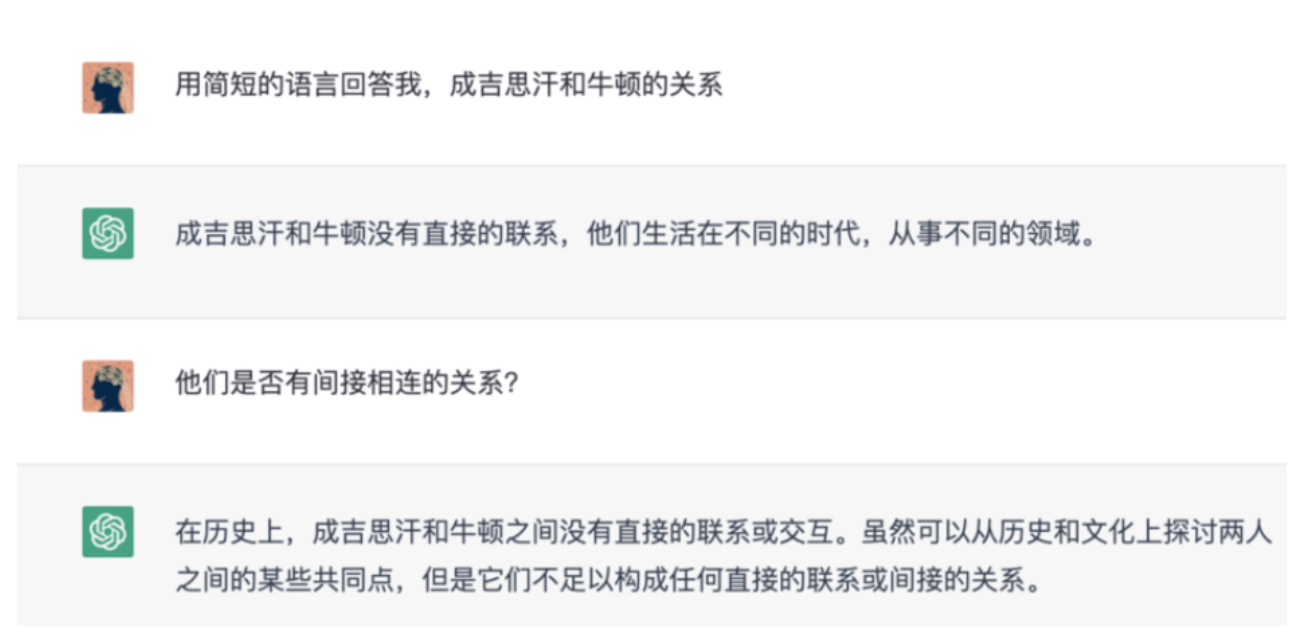
图:大模型无法实现(或替代)图数据库的深层检索
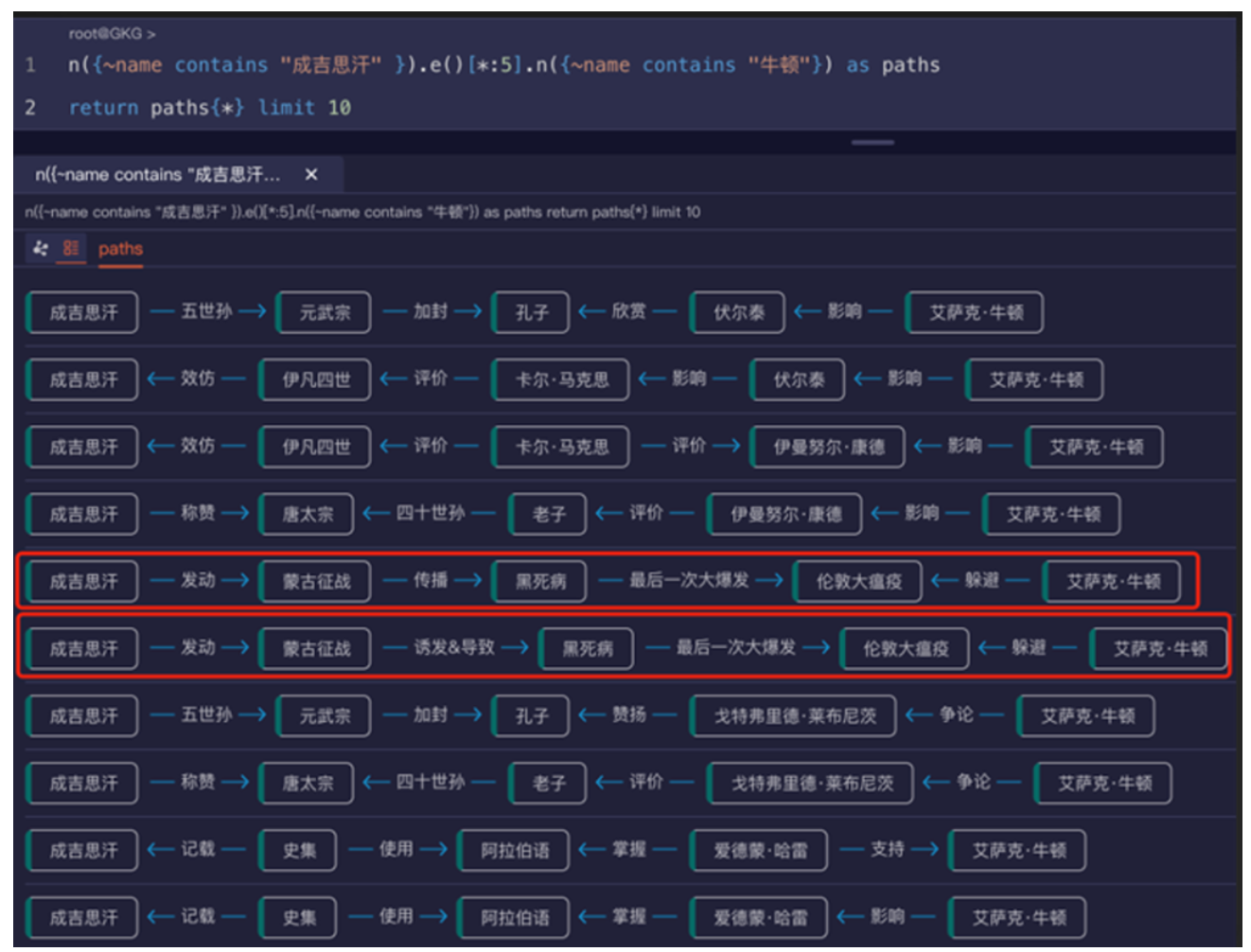
图:图数据库的海量结构化(深度、精准、白盒化)查询可以直接增强 LLM大模型能力
当前,AI 的需求与所提供的算力大多仍处于较为浅表的层面。尽管从自然语言处理的角度来看,它已能毫无语言障碍(包括跨语言障碍)地将内容组装成自然语言,这看似十分神奇。前些年,尤其在国内,娱乐应用盛行,如 AI 换脸、换声以及 AI 数字人(不少银行也在采用数字人)。然而,遗憾的是,这些都只是 AI 的初级互动形式。AI 的应用不仅面向消费者(to-C),也会面向企业(to-B)。对于真正企业级、严肃且专业的应用,包括接入大模型的 Copilot 以及各类 Agent,并将其引入企业内部,今年,特别是在中国,大量企业可能会引入内部 AI 工具,用于办公增强和流程自动化。但这是否真的改变了生产方式,目前还是个巨大的未知数,无人能给出确切答案。例如,对于一家保险公司或银行而言,原本有 500 名客服,使用 AI 后减少 400 人,实现 80% 的人员缩减,这是完全有可能发生的情况,然而我们实际上仍无法确定。
另外,未来 AI 必定会深入到决策支撑层面。三十年前,了解全球通信行业发展的朋友应该知道 boss 系统(业务运营支撑系统)。在 20 世纪 90 年代到 21 世纪初,中国很多上市软件公司都是靠做 boss 系统起步的。这里存在一个很有意思的现象,当年这类东西都被归为 IT 范畴,没人称其为 AI,但它们有很多相似之处。话说回来,未来的 AI 不再仅仅是 Copilot 这样的辅助角色,它将直接参与企业级、政府级、金融级甚至军事领域等各种层面的决策。
随之而来的问题是,AI 会不会被滥用?答案是肯定的,AI 几乎百分百会面临被滥用的情况。这就引出了一系列关键问题,比如 AI 的公平性、正义性、透明度、可解释性以及责任归属该如何界定。而这完全取决于 AI 的创造者与使用者。使用者的意图至关重要,他们是想用 AI 造福人类,还是另有所图,这值得我们深入思考。
此外,还有 AI 驱动的自治系统,例如机器人、自动驾驶以及智能投顾等。以自动驾驶为例,当达到最高等级 Level 5 的全自动驾驶时,车辆不再仅仅是辅助驾驶,而是能独立执行任务。在优先级设置方面,这类系统甚至反过来可以干预人类的决策。
但是,现阶段的 AI 是否具备真正的推理与自适应能力呢?实际上,很多专家早已对这一问题提出了质疑。目前,绝大多数的 AI 在本质上仍然只是模式匹配的增强版自动化。从底层原理来看,它们依旧在进行概率计算,这与人类的决策模式并不完全相同。当然,我们不能否认,在人类中也存在部分人采用模式匹配的思考和运行方式,但倘若所有的机器都仅仅如此,那么很明显,这些 AI 不一定能够适应所有的人。
还有一个不容忽视的问题,那就是监管。毋庸置疑,当前监管的步伐是滞后于 AI 发展的,这是一个全球性的普遍难题,没有任何一个国家能够宣称自己的监管机制以及伦理框架已经足够成熟,能够完美适配 AI 的发展现状,目前没有任何一个国家能做到这一点。
在监管领域,存在着诸多悬而未决的问题,涵盖数据安全、版权归属以及责任认定等多个方面。我们甚至可以预见到,那些在 AI 领域处于领先地位的大国,必然会采取各不相同的 AI 监管策略。例如,有的国家可能会依靠开放的市场力量来驱动 AI 发展,而有的国家则会凭借国家意志,实施自上而下的国家级战略,其中可能包含各种各样的限制性举措。以欧盟为例,从前些年颁布的《通用数据保护条例》(GDPR,General Data Protection Regulation )中,便能看出其监管特点的一些端倪,欧盟在数据隐私保护方面执行着极为严格的标准。

再来看第三个,也是最后一个议题。其实原来这个内容是个英文的内容,我将其译成了中文。在翻译过程中,我深刻体会到中文与英文在表达上往往存在着较大的语义差异。目前,我将英文单词 “Consciousness” 翻译成了 “意识层级”,但实际上,这样的翻译并不准确。“Consciousness” 这个词确实很难用中文精确地表达出来。究竟该把它理解为 “良知”,还是 “意识的层级” 呢?对于这一点,我自己也把握不太好。
本质而言,我想表达的概念是,无论是 AI 的创造者,还是消费者,他们自身的良知、意识的层级、思维的模式以及世界观,在很大程度上都会对 AI 工具、AI 产品以及 AI 平台的性质产生决定性影响。具体来讲,创造者的这些内在特质会在其打造 AI 工具、产品和平台的过程中得以体现,从而塑造出相应的性质特点;而消费者的这些方面,也会在与 AI 的交互和使用中,影响着 AI 的发展方向和实际应用效果,进而对 AI 工具、产品和平台的性质产生作用 。
我们不妨思考这样一个问题:为什么自2024年起,市面上众多公司“纷纷转型”,摇身一变、动辄就宣称自己是AI公司呢?这一现象与二三十年前传统公司开始涉足IT领域、接触信息科技时颇为相似,如今也是如此,大量公司在营销方面都选择“蹭热度”,如果一家公司不宣称自己是AI公司,就如同30年前不宣称自己是科技或IT公司一样,会面临被嘲笑、贬低和蔑视的境遇,公司的估值也会随之降低,这着实是一件令人遗憾的事情。由此可见,所谓AI的价值导向,在很大程度上受到了创造者和开发者的影响,比如他们的意识层级等因素,都在左右着AI价值导向的形成与发展。
AI 的本质实则是开发者价值观的一种外在体现和延伸。事实上,AI 并非是当下才出现的新生事物,早在之前就已存在。以推荐算法为例,像快手、抖音以及 YouTube 的推荐算法,按照如今对 AI 的定义,这些算法本质上都属于 AI 的范畴。无论是短视频还是长视频平台,它们的算法往往都在驱动用户沉迷其中,因为平台的目的是要最大限度地提升用户粘性。就如同早期互联网中存在的每用户平均收入(ARPU)概念,这在某种程度上也类似于“奶头乐”理论。虽然不能排除部分平台确实在提供知识增量,但从主体来看,情况并非如此。再看生成式 AI,我们去看它背后的数据集、训练方式以及优化目标,不难发现这些因素在很大程度上决定了 AI 会更倾向于与创造者和服务提供者的某些思维方式以及良知相契合。所以可以说,AI 的创造者决定了 AI 价值链条的最终走向。
在这个过程当中,我们无论是创造者还是消费者,都决定AI价值链的终局。昨晚思考到这一点时,我突然想到了几个 “心”。对于每个创造者而言,在创造 AI 的过程中,是否存在私心呢?虽然不排除有些人怀有爱心进行创造,但像那些让学生、儿童沉迷于短视频推荐算法的情况,以及宣扬 “学习无用论” 等现象,着实令人感到糟心和恶心。那么,如何才能让更多来自全球的用户放宽心呢?AI 的使用者也在塑造着 AI 的发展方向。我们需要思考的是,究竟是将 AI 仅仅作为一个简单的工具,还是让它成为一种真正由良知驱动的创新力量呢?这不仅是一个涉及伦理道德的问题,更是关乎人类进化的重要议题。
显然,AI 绝非仅仅是一个简单的计算问题。有些学者专家曾指出,这是一个哲学问题。但在我看来,它的范畴远不止于此,AI 是全人类都需要深入思考的议题。我们该如何去创造 AI,而 AI 又在反向影响并塑造着我们的生活,相信大家对此都深有体会。
通过观察我发现,处于不同意识层级的人,在对 AI 的创造和消费行为上存在着巨大差异。不知道大家是否留意到,近年来,越来越多的人选择离开朋友圈。这是为什么呢?因为人们在朋友圈中很难获取到有价值的营养、知识以及有用的信息。AI 工具也存在类似的情况,当你使用得越久、越深入,就可能会发现它不过如此,甚至会暴露出更多的问题。当然,倘若我们具备更强的能力,便有可能创造出更好的方案、思路,从更好的维度和角度去改进 AI。
我们之所以会产生这样的想法,正是因为每个人的意识层级各不相同,而这种意识层级的差异也导致了每个人在面对 AI 时的变化有所不同。实际上,我们每一个人都不仅仅是 AI 发展过程中的经历者,同时也是它的创造者,在 AI 的发展进程中扮演着不可或缺的角色。



